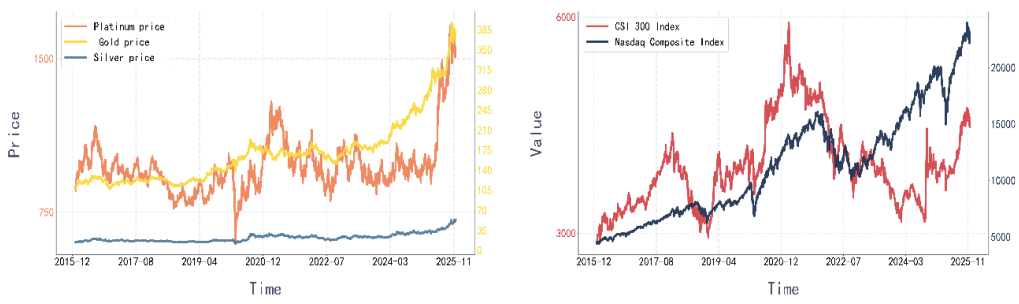
Against the backdrop of deepening global financial integration, the linkage between precious metals and stock markets has become a key issue in asset allocation and financial risk management. Existing studies mainly focus on lower-order interactions between the two asset classes, making it difficult to capture higher-order nonlinear interdependencies in multi-asset systems or to distinguish between redundancy and synergy effects. To address this gap, this paper investigates Gold, Silver, Platinum, the CSI 300 Index, and the Nasdaq Composite Index over the period from January 2016 to November 2025. Based on information dynamics, we construct a multi-resolution higher-order interaction (HOI) framework at the global, node, and link levels, derive the core O-information rate (OIR) measures under a vector autoregressive framework, and divide the sample into the Full Sample Period, Bull Market Period, Bear Market Period, and Recent Period. The results show that the five-dimensional cross-market system is overall dominated by redundancy effects. Precious metals are the main contributors to system redundancy, whereas stock indices are the primary sources of cross-market higher-order synergy. At the link level, intra-precious-metals pairs constitute the core redundancy channels, while cross-category pairs and intra-equity links are generally balanced between synergy and redundancy, except during the Bear Market Period, when significant cross-category synergy emerges. These findings provide a new perspective for understanding cross-market interactions and offer a useful framework for financial market analysis.